Match Fields
If you wish to add documents to existing records in docMgt then you would use this screen.
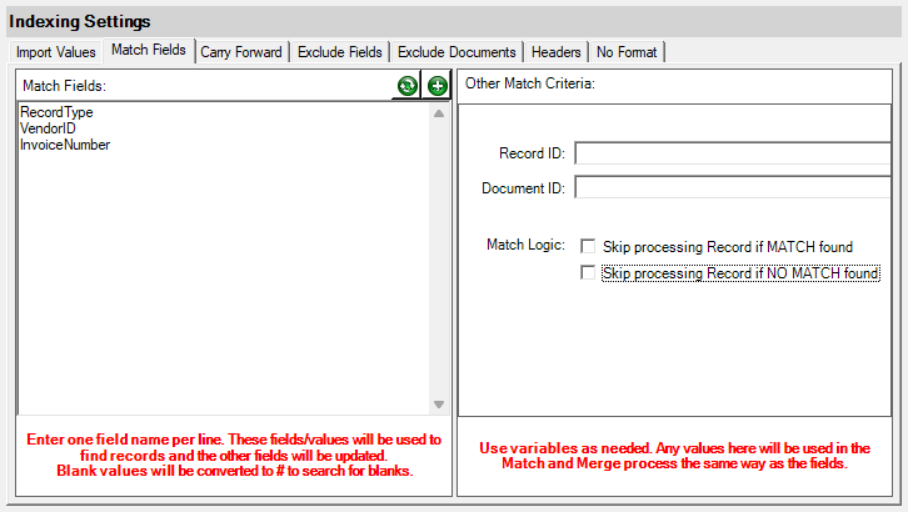
Simply add the field names by which to look for matches on the server. The importer will then look for records that have the same field names and the same values as the incoming record. If a match is found then the documents are added to that record. If no match is found then a new record is created.
You can click on the Add Fields from Record Type icon  to get a list of fields from the server based on the record type.
to get a list of fields from the server based on the record type.
NOTE: If you have blank values in the fields that are used for match and merge, Importer will look for blank values to match on. This can cause issues depending on your use case. If you wish to match and merge only when there is a value in that field then use the exclamation point (!) before the value. This will make Importer NOT use that value for matches. For example, if you have an Account Number field called ACCTNUM and want to only match when there is an account number in the data field, use !ACCTNUM as the match field name.
Other Match Criteria
You can also take in values that represent the Record ID or Document ID to match against. For instance, if you are importing a CSV and one of the columns has the ID of the Record you wish to import into you can use that column in the Record ID field. You would use the column (header) name in brackets. If the column name was RECID then you would use [RECID] in the Record ID field. Importer will use the value in that column to find a matching Record to import into or update.
Skip processing Record if MATCH found - Turn this on ONLY if you are configuring a Match and Merge process where you only want to upload new Records and not update existing ones.
Skip processing Record if NO MATCH found - Turn this on ONLY if you are configuring a Match and Merge process where you only want to update existing Records and not add new ones.
ADVANCED USES
Variables in Match and Merge
As of version 3.26 you can use custom mapping for the Match and Merge function. Each line in the mapping field still relates to one search field but you can now customize that using a FIELDNAME:FIELDVALUE template. The FieldName and FieldValue values can use variables as well. Here is an example:
EmployeeName:%[SPLIT([FILENAMEONLY]| |1)]%
EmployeeName:%[SPLIT([FILENAMEONLY]| |2)]%
This will split the FileNameOnly with spaces and will look for any Records where EmployeeName contains the first or second element. This results in logic like this (pseudo code):
"Find all records where EmployeeName contains the first value split by spaces AND the second value split by spaces"
Match Using Record ID
As of version 3.29 you can use RECORDID:FieldName to be able to search for a match by the Record's ID
RECORDID:[ID]
This will use whatever is in the incoming data's ID field and use that to look for a matching Record whose ID value matches that number. This is very useful in cases where you have exported data, made changes and want to import the changed data back into the same Records.